DeepSeek-V3.2-Exp in vLLM: Fine-Grained Sparse Attention in Action
Introduction
We are excited to announce the Day 0 support of DeepSeek-V3.2-Exp (LINK TO MODEL ON HF), featuring DeepSeek Sparse Attention (DSA) (LINK TO PAPER) designed for long context tasks. In this post, we showcase how to use this model in vLLM and deep dive into the challenges encountered in supporting DSA in vLLM.
In particular, DSA’s lightning indexer indexer along with sparse attention presents challenges in continuous batching and paged attention. For example, we need to take care of prefill and decode separately for the indexer module and carefully manage the different cache layouts.
On the performance side, vLLM integrates with the lightning indexer CUDA kernels in DeepGEMM, as well as the new sparse attention kernel in FlashMLA. We are also excited about the Blackwell support. In collaboration with NVIDIA, you can run this model directly on B200 and GB200!

Figure 1: Illustration of DeepSeek Sparse Attention (DSA) Mechanism.
Usage Guide
To get started with DeepSeek 3.2, please follow the installation instructions in the recipes. We are still improving the initial support with PR and for known issues see tracking issue.
Once installed, on 16xH100, 8xH200 or 8xB200, you can run the model with tensor parallelism (expert parallelism has a slight bug we are fixing):
vllm serve deepseek-ai/DeepSeek-V3.2-Exp --tensor-parallel-size 8
To deploy at scale, we look forward to sharing our one click Kubernetes deployment using llm-d later this week. This approach launches vLLM with PD disaggregation with NIXL, then for each P and D instance, efficiently route requests to different data parallel ranks. See documentation here.
Once you start the engine, we recommend testing it with long input or prompt expecting long output. We recommend comparing it with V3.1-Terminus as it is continuously pre-trained on the same data mix.
We are still in process of verifying vLLM’s implementation against the official accuracy result. On a previous version of the model weights, we matched expected GSM8K and GPQA-Diamond scores, and showcase it is similar to V3.1-Terminus.
Implementation of Top-K Sparse Attention in vLLM
New Cache Entry and Quantization Scheme
The lightning indexer module has cached K values specifically for indexing. This means for each token, there’s now another K cache used by the indexer. vLLM allocates separate buffers to save the indexer K cache separated from MLA K cache.
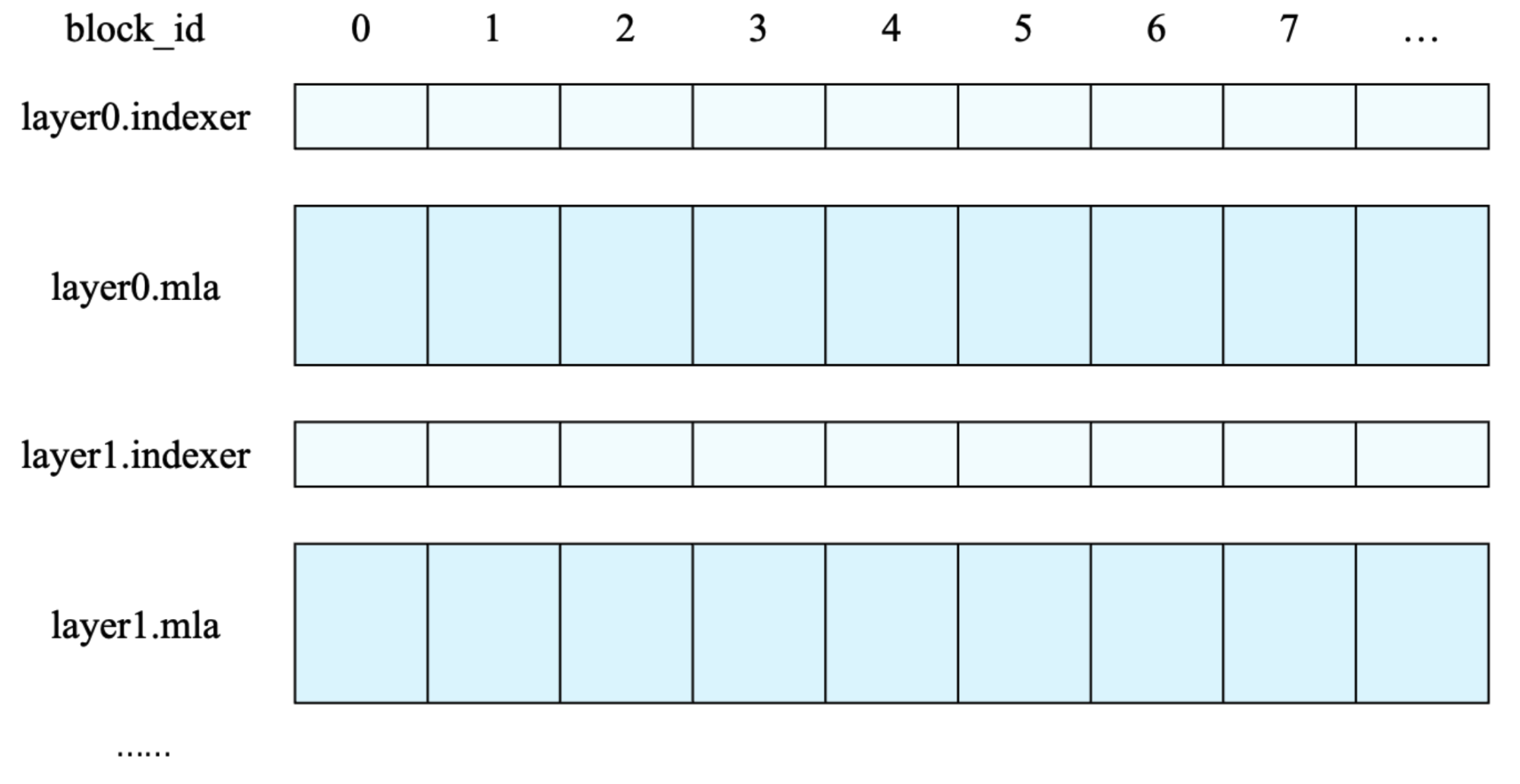
One more interesting point is the handling of the FP8 KV cache, which this model supports. For MLA, each token’s KV cache is 656 Bytes, structured as:
- First 512 bytes: The “quantized NoPE” part, containing 512
float8_e4m3values. - Next 16 bytes: Scale factors, containing 4
float32values. The firstfloat32is the scale for the first 128float8_e4m3values, the second for the next 128, and so on. - Last 128 bytes: The “RoPE” part, containing 64
bfloat16values. This part is not quantized for accuracy.
But for indexer key cache, it is stored as a per block basis. This is one of the reasons we only support block size 64 for this model; the other being FlashMLA is tailored to it as well. The first block_size * head_dim entries contains the value, the rest contains the scaling factor:
x_fp8[ :, : block_size * head_dim] = x_scaled.view(num_blocks, block_size * head_dim).view(dtype=torch.uint8)
x_fp8[ :, block_size * head_dim :] = scales.view(num_blocks, block_size).view(dtype=torch.uint8)
In the indexer, the cache of one token is not stored contiguously.
New Computation with Masking
For each new query token, it now passes through the indexer to compute top 2048 tokens to attend to. For a query of a token is a tensor of shape (h, d), with h being the number of query heads, and d being the head dimension. The context of size n is a 2D tensor of shape (n, d). The computed logits (relevance score between the query and the context) are a tensor of shape (n, h). Weighting the logits by the head weights of shape (h,), we get a tensor of shape (n,). We need to produce a (2048,) integer tensor of the indices of the top-2048 tokens, with -1 filled for the rest if there are less than 2048 tokens.
While it’s straightforward to see how a single query token selects indices to attend to. The batching case is more complicated, let’s break it down.
The new DeepGemm function is called like the following
logits = deep_gemm.fp8_mqa_logits(q_fp8, kv_fp8, weights, ks, ke)
For several query tokens (length q) from the same request (i.e. the prefill case). They are stored in a tensor of shape (q, h, d). The context still has n tokens, so the context is still a 2D tensor of shape (n, d). The logits are a tensor of shape (q, n, h). Weighting the logits by the head weights, we get a tensor of shape (q, n). We need to produce a (q, 2048) integer tensor of the indices of the top-2048 tokens. Due to causality, every query token only attends to the tokens before it. We need to mark the start context and the end context for each query token. We use ks to mark the start context, and ke to mark the end context. ks and ke are both (q,) shaped integer tensors. In this case, ks will be all zeros, and ke will be a list(range(n - q, n, 1)).
Finally, let’s consider how to batch multiple requests. We have b requests, each request has q1, q2, ..., qb query tokens, and n1, n2, ..., nb context tokens. The query tokens will be batched into a tensor of shape (q1 + q2 + ... + qb, h, d). The context will be batched into a tensor of shape (n1 + n2 + ... + nb, d). The logits will be batched into a tensor of shape (q1 + q2 + ... + qb, n1 + n2 + ... + nb, h). We need to produce a (q1 + q2 + ... + qb, 2048) integer tensor of the indices of the top-2048 tokens.
We need to mark the start context and the end context for each query token. We use `ks` to mark the start context, and ke to mark the end context. ks and ke are both (q1 + q2 + ... + qb,) shaped integer tensors.
In this case, ks will be [0] * q1 + [q1] * q2 + ... + [q1 + q2 + ... + qb] * qb. Here * means repeating the list. ke will be list(range(n1 - q1, n1, 1)) + list(range(n2 - q2, n2, 1)) + ... + list(range(nb - qb, nb, 1)) plus the offset of ks.
After the logits, we need to perform the topk operation. However, a clear challenge is at high batch size with long context, the logits tensor is materialized before running a row-wise topk. The vLLM team is working on a fused version inspired by FlashAttention, we can run an online topk in a way we don’t need to materialize the intermediate logits.
Fusion pass, more kernels, and Blackwell Support
As we starting to optimize the performance, we started with a few low hanging fruit:
- Top K can be expressed with a fused kernel with better performance. The TileLang kernel from the DeepSeek team serves as great references!
- We used the quantization of MLA latent and indexer key vectors as they are writing to vLLM’s page table. This turns out to be non-trivial as we previously explained that the quantization scheme is new and different.
We are also excited to announce the out of the box Blackwell support for this model. We strive to make Blackwell platform a first class citizen in model releases going forward, as its efficiency helps bring out the best performance!
Ongoing Work
We are barely touching the surface of the optimization for DSA and related sparse attention in vLLM. In coming weeks,
- We plan to expand the architectures supported beyond Hopper and Blackwell.
- We will bring in AMD support as well.
- We continuously test large scale wide EP serving and disaggregation.
- You will soon be able to run an end to end RL loop with this model.
- We will explore the “masked MHA mode for short sequence prefilling” from DeepSeek
- In this release, we removed Hadamard transforms as we observe no effect on accuracy. We will investigate further!
Acknowledgement
The following team in the vLLM community worked on this model’s support:
- vLLM core: Chen Zhang, Yongye Zhu, Kaichao You, Simon Mo, Zhuohan Li
- Red Hat: Lucas Wilkinson, Matt Bonanni, Wentao Ye, Nicolo Lucchesi, Michael Goin, Robert Shaw, Tyler Michael Smith
- Meta: Lucia Fang, Xiaozhu Meng, Lu Fang
- NVIDIA: Ray Wang, Barry Kang, Daniel Campora, Julien Demouth, Siyuan Fu, Zeyu Wang, Pen Chun Li
As the vLLM team, we want to thank DeepSeek team for open sourcing this model, techniques, and kernels, as well as DeepSeek leadership for trust and support in vLLM!